Performance comparison of PostgreSQL connectors in Matlab, Part II: retrieving scalar data
In Part I of this paper we started our investigation of PostgreSQL connectors in Matlab. Namely, we compared the performance of different approaches to insert data into the PostgreSQL database. Some of those approaches are based on using Matlab Database Toolbox (working with PosgteSQL via a direct JDBC connection). Other ones are based on PgMex library (providing a connection to PostgreSQL via libpq library). Here we continue the comparison of Matlab Database Toolbox and PgMex library considering data retrieval. The given part of this paper covers retrieving only in the most simple case of scalar data, both of numeric and non-numeric types.
In the performance benchmarks below we use the same data that was used in the previous article for data insertion benchmarks. As was mentioned previously, this data is based on daily prices of real stocks on some exchanges. Given the nature of such a financial data it is quite easy to image a few real-world scenarios where a possibility to retrieve this data in a large amounts very quickly is very important. Below we reveal some latent restrictions (concerning both performance, volumes and type of data to be processed) that do not allow our development team to use Matlab Database Toolbox in such scenarios. An alternative solution, PgMex library, was developed by our team to overcome these restrictions and to allow us to efficiently solve financial data processing problems.
Before we start, let us recall very shortly the structure of the test data we use. This is necessary to indicate below the specifics of the corresponding fields in each of the cases under consideration. These fields are as follows (their types are pointed in the terms of PostgreSQL):
- t_data of date type determining trading dates
- inst_id of int4 with internal identifiers of instruments (unique for each stock)
- price_low of float4 with low prices of stocks (adjusted for splits)
- price_open of float4 with open prices of stocks (adjusted for splits)
- price_close of float4 with close prices of stocks (adjusted for splits)
- price_close_ini of float4 with close prices of stocks unadjusted for splits
- price_high of float4 with high prices of stocks (adjusted for splits)
- price_close_opt of float4 with close prices of stocks unadjusted for splits and used in the Black-Sholes formula
- volume of int8 with traded volumes
- calc_date of date type with dates when calculations were done
All the experiments below are grouped according to the types of fields retrieved from the database simultaneously. That is we may retrieve only some subset of the fields just mentioned above. We discuss two cases: pure numerical data and data with timestamps. What concerns conditions of the experiments, they are exactly the same as in Part I.
Methods of data retrieval in Matlab Database Toolbox
There are two ways to retrieve data from the database by means of Matlab Database Toolbox. The first is based on a selection query by calling exec method of database.jdbc.connection class. This exec returns an object of database.jdbc.cursor class. After this we may retrieve results by calling fetch method of this database.jdbc.cursor object. Secondly, it is possible to get results immediately by calling fetch method of database.jdbc.database class. The differences of these methods have their nuances not relevant for our investigation.
You can read about these nuances at Matlab Help in details. But shortly speaking the first way is more flexible (it allows to limit the total number of rows returned, to determine whether fetching data in batches is to be used or not). This is why in this article we concentrate on using exec and fetch.
There are three important parameters set via setdbprefs function. They determine the format, in which Matlab Database Toolbox returns results of data retrieval. Their names are DataReturnFormat, NullNumberRead and NullStringRead. The parameter DataReturnFormat defines the way data is represented in Matlab, and can take three possible values: ‘cellarray’, ‘numeric’, and ‘structure’.
If DataReturnFormat equals ‘cellarray’, data is returned as a two-dimensional cell array. At that each cell contains the value of some field for some tuple. The field corresponds to the column number of this cell within the whole cell array, while the tuple is determined by its row number. NullNumberRead and NullStringRead determine values that substitute NULL values (in case these values are to be returned as numbers and strings, respectively).
If DataReturnFormat is ‘numeric’, data is returned as a double matrix. Besides, NULL values of fields having numeric types are returned equal to the number given by NullNumberRead parameter. The latter number substitutes also all values of each field that is of non-numeric type.
At last, if DataReturnFormat is equal to ‘structure’, then the data is returned as a structure with fields corresponding to the fields of retrieved table. The fields of this structure have the same names as in this table. The representation of NULL values in Matlab is configured by NullNumberRead and NullStringRead (exactly as above in case DataReturnFormat equals ‘cellarray’).
Methods of data retrieval in PgMex
The same problem of data retrieval can be solved via PgMex in a way very similar to the one described above. PgMex implements two commands: exec for execution of queries returning a pointer to PGresult structure with results and getf for transforming the mentioned PGresult structure into a Matlab friendly format. More precisely, getf returns a list of structures, one structure per each field of retrieved table. Each structure has three fields:
- valueVec - a vector of values extracted from the database;
- isNullVec - a logical vector with indicators of value elements being NULL;
- isValueNullVec - a logical vector with indicators of entire table cell (a field in a specific tuple) being NULL.
isNullVec and isValueNullVec differ only for fields of array type. But in the present Part II of the paper we deal only with fields of scalar types (the case of array types is an object for further investigations). Hence, just for simplicity in this article we may assume that isNullVec and isValueNullVec are the same.
When compared with Matlab Database Toolbox, PgMex provides much more safe and consistent way of representing NULLs. In fact, with Matlab Database Toolbox for NullNumberRead set to NaN ordinary NaN values may be easily confused with NULLs. The same is true for NullStringRead parameter. Thus, for Matlab Database Toolbox one needs to assume in advance that certain numerical or, respectively, string values cannot appear among “ordinary” ones.
Retrieving scalar numericals
Retrieving only fields of scalar numeric types can be done in all three result formats supported by Matlab Database Toolbox determined by DataReturnFormat parameter including ‘numeric’. But it turns out that fetch converts returned numericals to double Matlab regardless of DataReturnFormat value. This leads to a few rather serious drawbacks:
- when DataReturnFormat equals ‘numeric’, fields of non-numeric types are not to be retrieved, because otherwise their values are fully lost;
- conversion inaccuracies are possible;
- returned data has a larger size than really necessary.
Let us have a look at a few examples for each of these problems and explain the corresponding side-effects in more details.
Firstly, if DataReturnFormat is set to ‘numeric’ and returned data has non-numeric fields, all their values are lost in the resulting matrix. This is because fetch simply replaces all values for such fields with NullNumberRead not being able to convert them to double. Hence, we are forced to exclude all non-numeric fields like t_data and calc_date from our selection query. This may seem rather strange, because in Matlab timestamps are naturally represented by serial date numbers (of double type). But the point is Matlab Database Toolbox always returns timestamps as strings. So the case of DataReturnFormat being set to ‘numeric’ is not applicable for retrieving timestamps. That is why we consider retrieving timestamps data separately in the next subsection.
Other two drawbacks are valid for all values of DataReturnFormat. As for conversions imprecisions, the problem is as follows. Each number of double Matlab type occupies 8 bytes, and only 52 bits from these 8 bytes are used for the fractional part (1 bit is for the sign, 11 bits are for the exponent). If we convert some int64 Matlab integer into double, these 52 bits may be insufficient to ensure an accurate value conversion. For instance, if we try to cast the maximal possible value of int64 equal to 9223372036854775807 to double, we obtain 9223372036854775800 instead of the original value. Hence we cannot be sure that such a conversion does not lead to the described data loss. And this problem is exactly there when we try to retrieve through fetch such fields as volume. This is because the latter has int8 type in PostgreSQL, that corresponds to int64 in Matlab.
Now let us assume that all the values to be retrieved can be cast into double without any data loss. But even in that situation we are left with the third drawback of very inefficient usage of operative memory. The most of the fields mentioned at the beginning of this article like price_low or price_close are of float4 type, i.e. each of their values occupies 4 bytes. And for our data set a result representation generated by fetch consumes almost twice more space than it should. That is because all the fields having float4 type correspond to single Matlab type, not double type. Obviously the situation could potentially be even worse if one has to retrieve logical values. In this case fetch representation would consume 8 times more RAM comparing to the original data size. This inefficient data representation in fetch results leads to a memory shortage when the total number of tuples to be returned is significant. This can be clearly seen on the following picture generated for DataReturnFormat equal to ‘numeric’, ‘cellarray’ and ‘structure’ respectively.
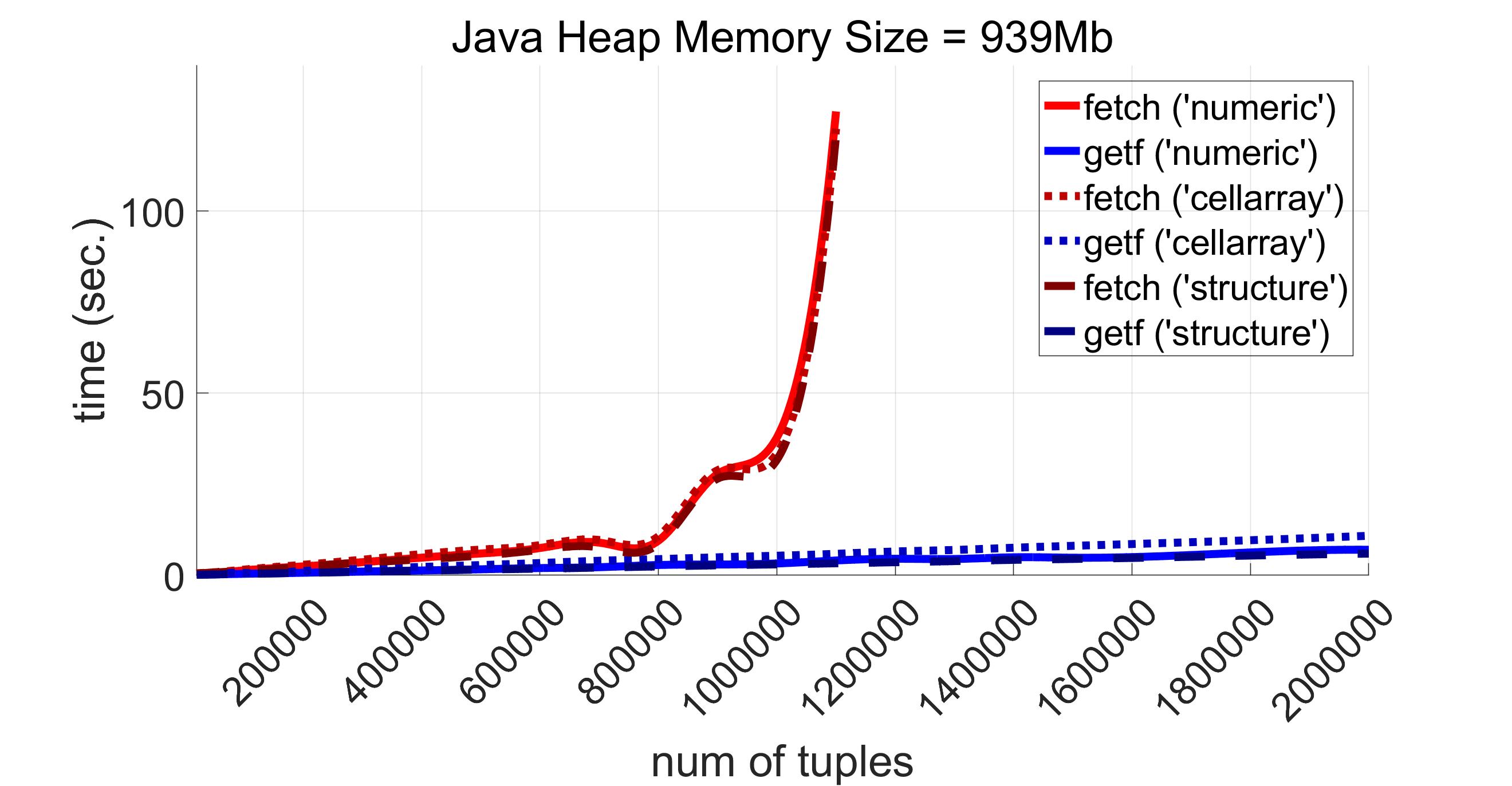
One can see all three red graphs on the picture above (they correspond to fetch) “break” when a number of tuples reaches 1200000. This is because exec throws exceptions in all modes determined by DataReturnFormat. The exception for ‘cellarray’ and ‘structure’ modes is the same and is as follows:
Exception for function fetch, number of tuples 1200000
Caused by:
Error using database.jdbc.cursor (line 229)
Java exception occurred:
java.lang.OutOfMemoryError: GC overhead limit exceeded
[see more...]
For ‘numeric’ mode the corresponding exception only slightly differs from the one above. The difference is just that the first line of the above stack trace is absent here.
It should be also noted that a memory size necessary for storing a retrieved data in Matlab is different for different values of DataReturnFormat. The memory consumption for the experiments above is shown in the following table.
| Number of tuples |
Data size for 'numeric mode' |
Data size for 'cellarray' mode |
Data size for 'structure' mode |
|---|---|---|---|
| 20000 | 1Mb | 18Mb | 1Mb |
| 40000 | 2Mb | 36Mb | 1Mb |
| 60000 | 4Mb | 53Mb | 2Mb |
| 80000 | 5Mb | 71Mb | 3Mb |
| 100000 | 6Mb | 89Mb | 3Mb |
The mentioned difference is explained as follows. In ‘cellarray’ mode we need to store each number in a separate cell. ‘numeric’ mode is almost twice more expensive than ‘structure’ because all numbers in ‘numeric’ mode are converted into double Matlab type. Thus, for 1200000 tuples critical to Matlab Database Toolbox this size is 73Mb for ‘numeric’ mode, 1067Mb for ‘cellarray’ mode and 41Mb for ‘structure’ mode.
Clearly all these fails have nothing to do with the result data format used by fetch. The reason is a shortage of Java Heap memory for storing results of the query to be executed by means of exec.
Starting with 1200000 tuples exec together with getf methods from PgMex are the only ones that successfully solve the problem of data retrieval. On our configuration PgMex retrieves the test data of 2000000 tuples (122Mb for ‘numeric’ mode, 1778Mb for ‘cellarray’ mode and 69Mb for ‘structure’ mode) approximately in 6 seconds.
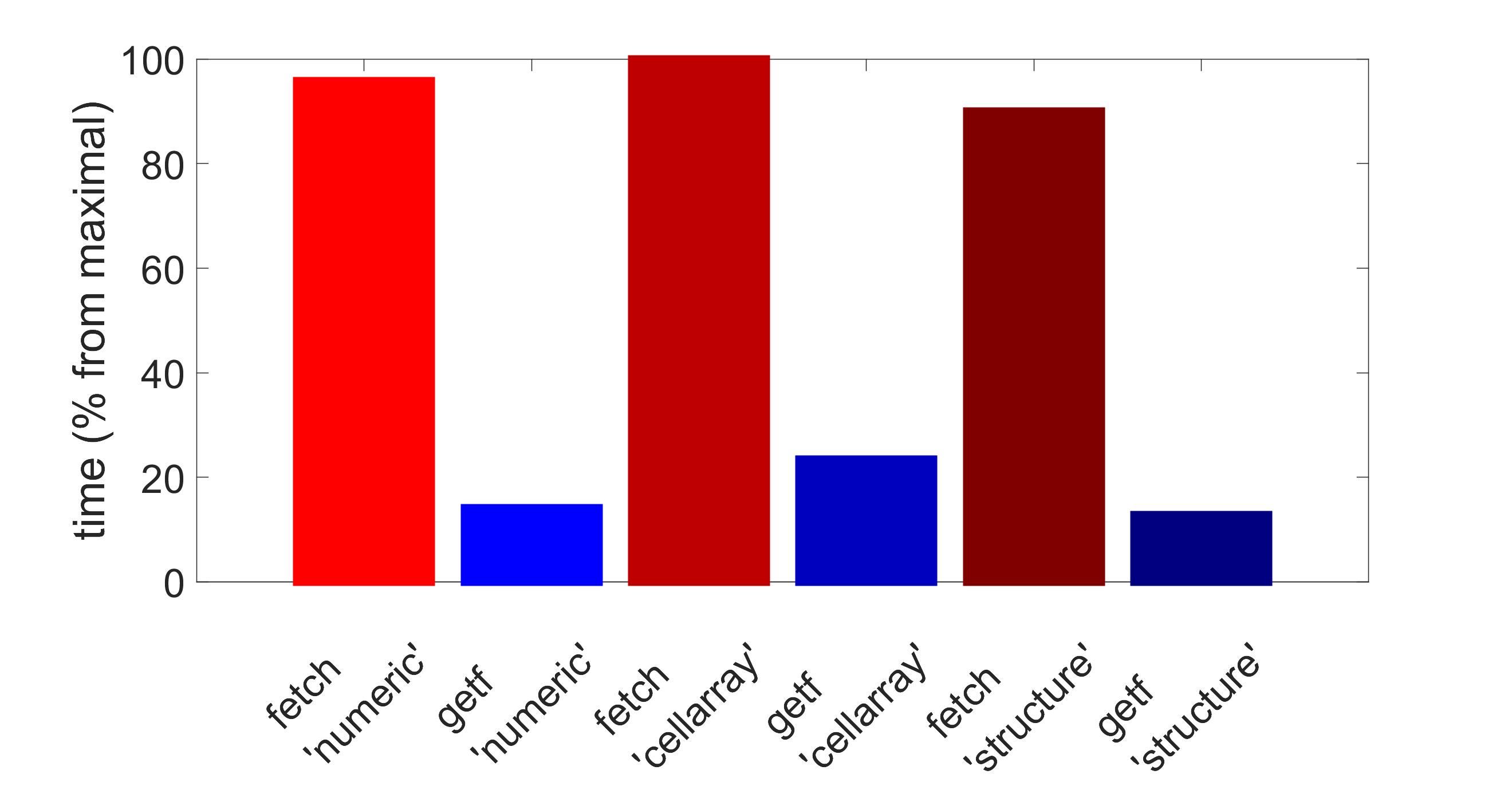
It turns out that if we only take a range [0, 1100000] for a number of tuples (as number of tuples = 1100000 is where the red graphs end) on average exec and getf are more than 7 times faster than exec together with fetch from Matlab Database Toolbox. Below are diagrams for ‘numeric’, ‘cellarray’ and ‘structure’ modes, respectively.
Retrieving timestamps
The gap in performance between exec and getf on one hand and exec with fetch from Matlab Database Toolbox on the other hand increases further when we try to retrieve all the fields from the data mentioned above with the fields t_data and calc_date containing dates. As already was said, Matlab Database Toolbox always returns values of date, time or timestamp types as strings. Besides, these strings may be returned only via placing them into a cell array. And there are two options. Firstly, if DataReturnMode equals ‘cellarray’, they are returned in the corresponding columns of a cell array containing all the retrieved results. Secondly, if DataReturnMode is ‘structure’, values for t_data and calc_date are placed into the respective fields of the returned structure as char cell arrays. When it comes to PgMex, no such a conversion is required, date, time and timestamp values may be processed as serial date numbers. The results for scalar data with timestamps are as follows:
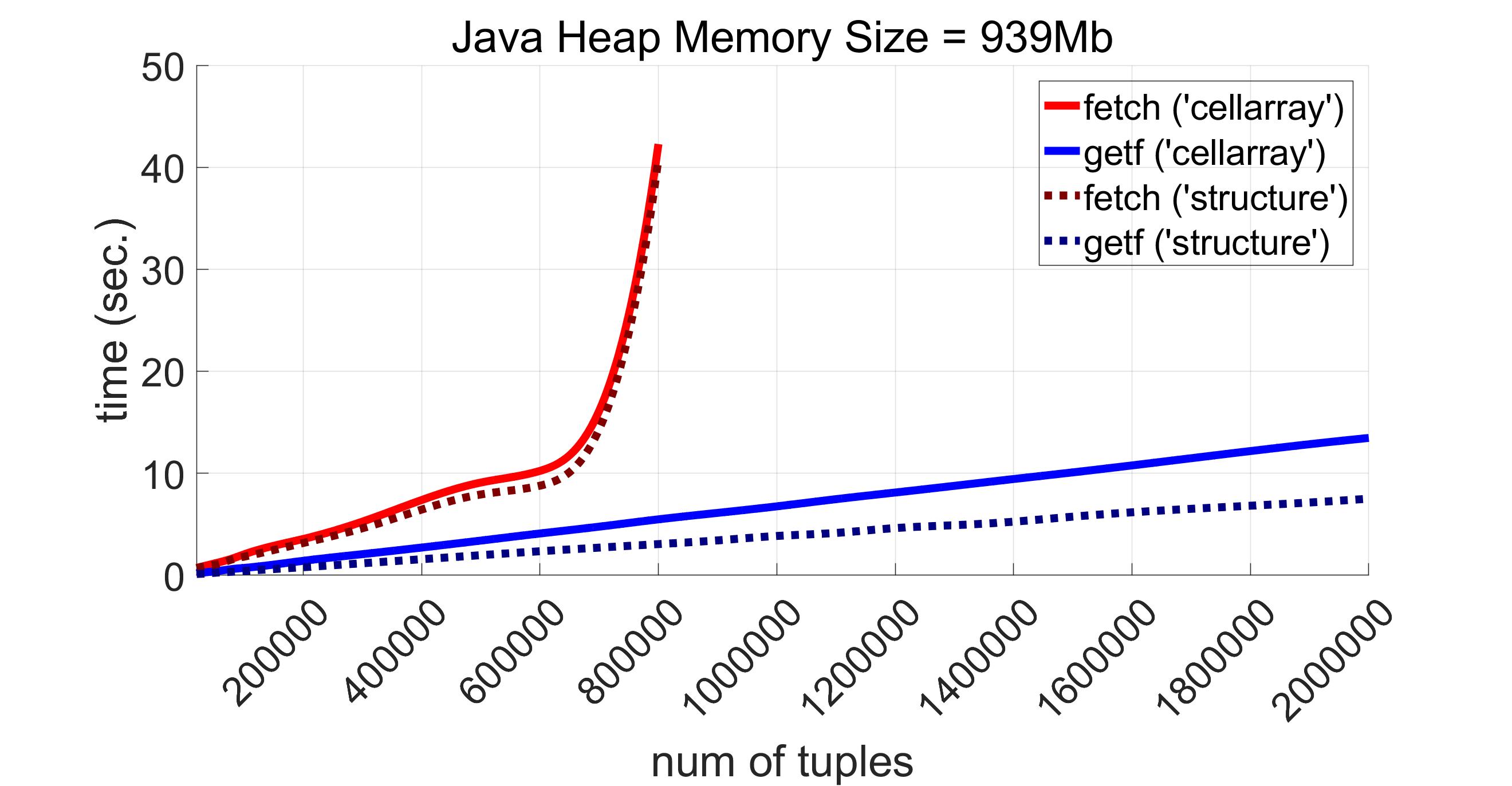
One can see that exec from Matlab Database Toolbox digests 800000 tuples (894Mb for ‘cellarray’ mode and 40Mb for ‘structure’ mode) (thanks to absence of converting numbers to some types of greater size), but fails to retrieve 900000 tuples (1000Mb for ‘cellarray’ mode and 45Mb for ‘structure’ mode) by throwing the following exceptions (the first one is for ‘cellarray’ mode, the second one is for ‘structure’ mode):
Exception for function fetch, number of tuples 900000
Caused by:
Error using database.jdbc.cursor/fetch (line 199)
Java exception occurred:
java.lang.OutOfMemoryError: GC overhead limit exceeded
[see more...]
Exception for function fetch, number of tuples 900000
Caused by:
Error using database.jdbc.cursor/fetch (line 199)
Java exception occurred:
java.lang.OutOfMemoryError: GC overhead limit exceeded
[see more...]
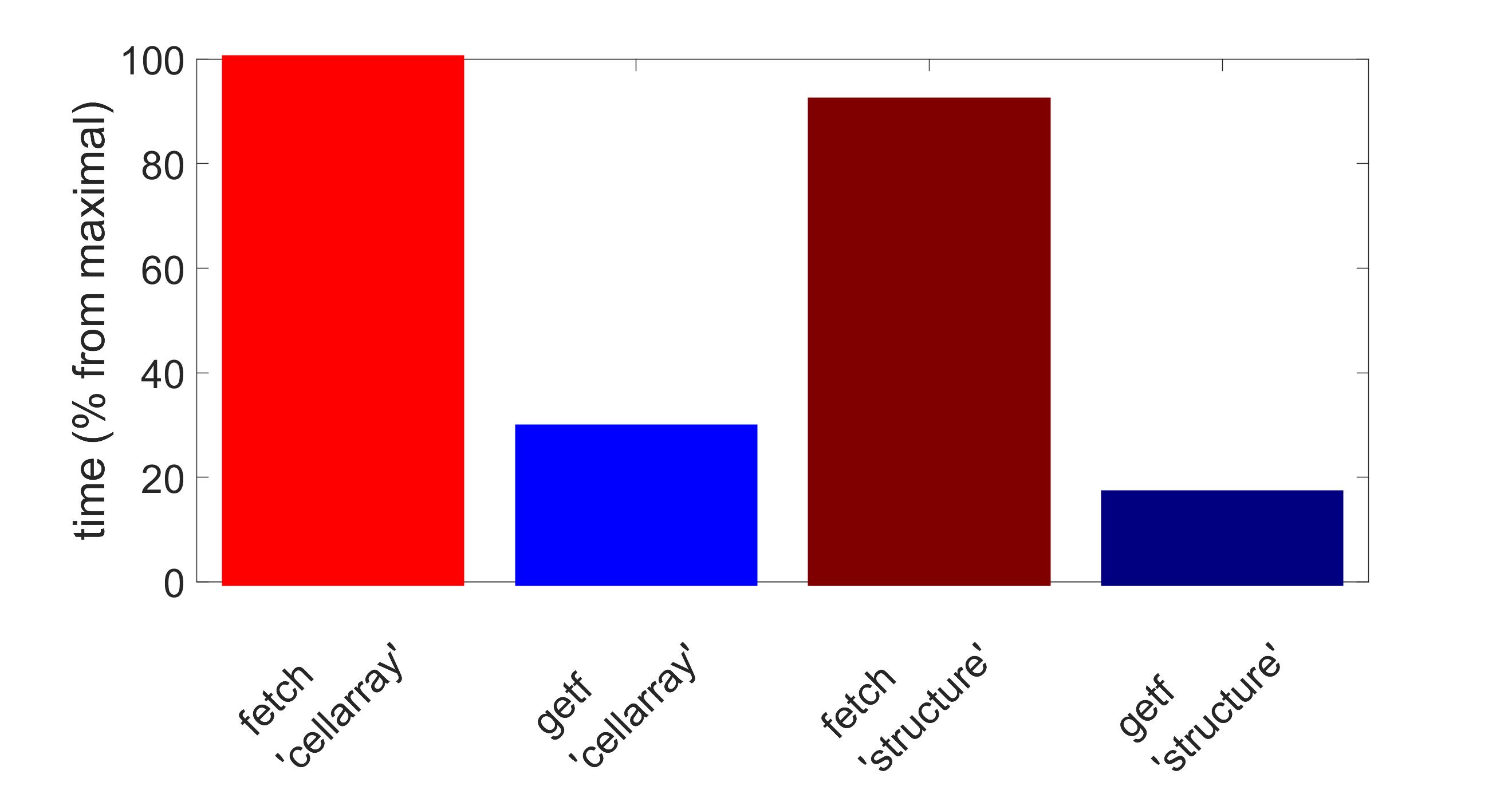
It can be noted that getf works slower for ‘cellarray’ mode than for ‘structure’ mode. This is explained by the overhead for conversion of values represented initially as column vectors into cell arrays (just to provide the same format of the output as fetch returns for ‘cellarray’ mode). If we measure the performance without this conversion overhead, the results are represented by the following diagrams:
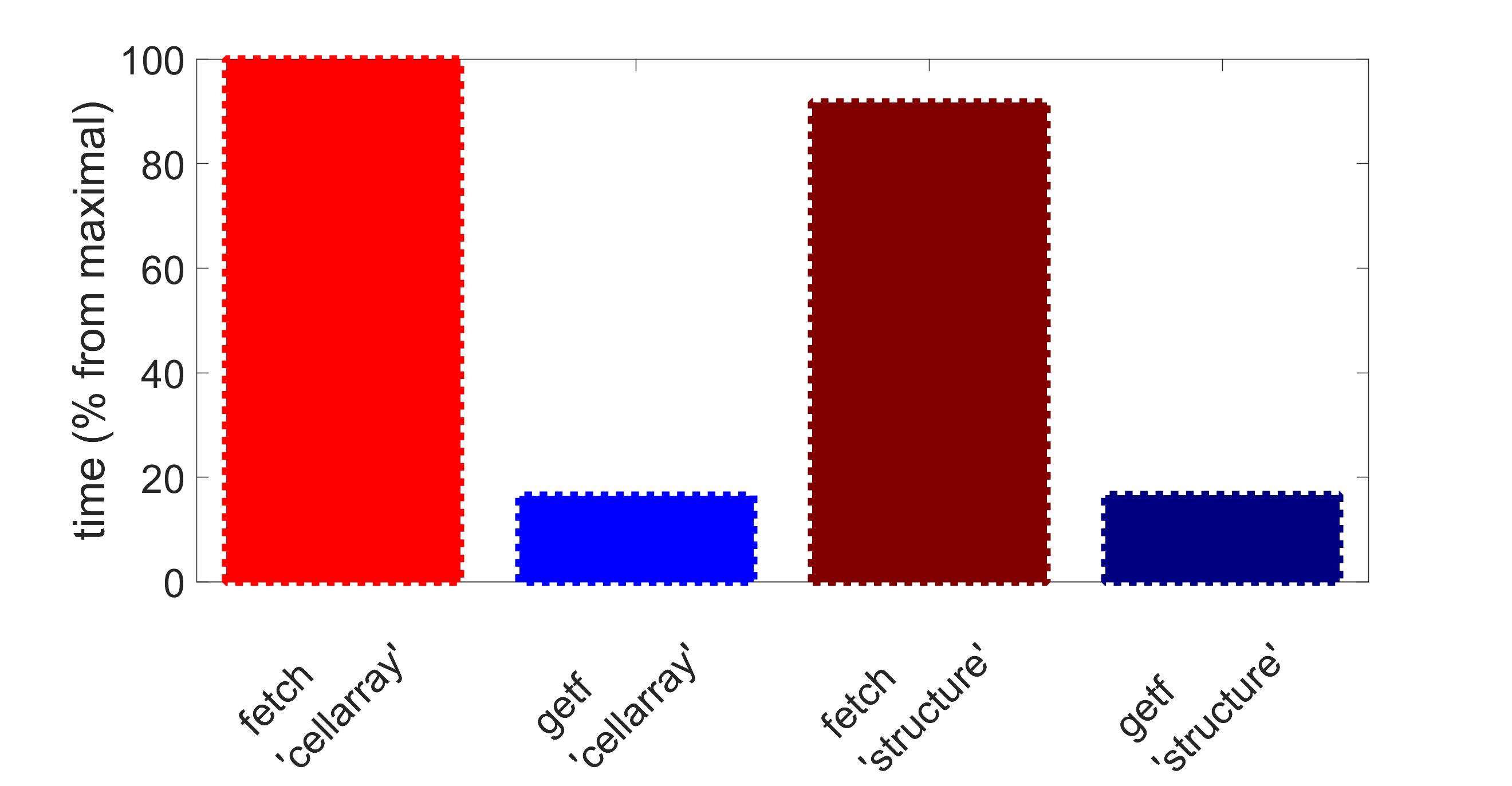
On average the execution time for exec along with getf is approximately 20% of that time for exec and fetch from Matlab Database Toolbox, at least for those volumes both function succeeded to retrieve.
Summary
So as we have seen, the functionality provided by Matlab Database Toolbox for JDBC connection to PostgreSQL has serious restrictions not only for inserting data, but also for its retrieval, especially for large datasets. The limitations of PgMex are sufficiently higher and this library is free from those shortcomings related to data types conversions (because it works with native Matlab formats).
In Part III of our performance research we will compare different ways to retrieve multidimensional data (of array type) from the database using both Matlab Database Toolbox and PgMex library.