Performance comparison of PostgreSQL connectors in Matlab, Part I: inserting data
We actively develop software related to financial modelling and risk estimation. Most of model prototypes basing on data mining, machine learning, quantitative analysis we develop as well as certain parts of production code (thanks for JIT compilation and rich visualization capabilities) are implemented in Matlab.
And naturally we always face the need to process huge amounts of financial data. Data processing usually generates even more data that needs to be stored somewhere in a persistent and consistent manner. There are many ways to achieve that, but for us the most reasonable choice is to use a relational database server. Certainly, there are numerous other way to approach this problem, ranging from using plain MAT files to using distributed and highly-scalable data storage systems. But those solutions is a compromise when it comes to data integrity and consistency - for instance MAT files may get corrupted at any time. Further, in case a model we develop include some parameters needed to be adjusted, we have to perform this adjustment by running a significant number of experiments. This is better to do in parallel, possibly on different computers. And in this situation an ability to collect results of experiments by network also becomes crucial.
Of course, there exist more appropriate solutions allowing to process big data sets parallel, for instance, Apache Hadoop. But most of Hadoop data stores support only eventual consistency working on the so-called BASE model of data (Basically Available, Soft state, Eventual consistency), not providing a principle called ACID (Atomicity, Consistency, Isolation, Durability). And this is namely the reason why such an approach does not suit us completely. Our data is highly structured and comes in a table-like form. Thus, it seems that the best choice in our case is an ACID compliant relation storage.
In our projects we use PostgreSQL which fully supports ACID (in contrast to some other relation databases like MySQL, not being fully ACID compliant), is free (we cannot afford Oracle, so it is also important for us) and open-source software, developed by an international team consisting of several companies as well as of individual contributors. PostgreSQL is thoroughly tested that makes it sufficiently reliable for our software. Another very crucial argument in favor of PostgreSQL is that it supports array types. Let us consider an example illustrating the importance of the latter along with some additional advantages of PostgreSQL.
One of our projects had to do with modeling implied volatility surfaces based on option prices. As the first step these surfaces have to be interpolated because raw data doesn’t contain their values on a regular grid in strike price (or Delta)/time to maturity space. The original surfaces contain a lot of data “holes” which occur when some options with similar parameters simply are not traded on the market. Making such an interpolation (taking into account volumes even of raw data) is not an easy to do in an computationally efficient way, especially given a limited amount of RAM on a server. We managed to implement such interpolation directly on PostgreSQL server. Moreover, for implied volatility surfaces it was natural and reasonable to use three-dimensional PostgreSQL arrays due to the parametrization mentioned above and dependency of these surfaces on time.
But to perform more intrinsic processing of data in Matlab it is necessary to have an interface between Matlab and PostgreSQL. The first solution that at first glance seems to be rather obvious is to use Matlab Database Toolbox working via a direct JDBC connection. But it turns out this “standard” solution has some latent restrictions (concerning both performance, volumes and type of data to be processed) that do not allow to use the toolbox in our projects. And the goal of this paper is to reveal these restrictions and to compare it to another solution. The latter one, namely, PgMex library, was developed by our team out of the necessity to work with big data of very diverse types (including arrays). PgMex library provides a connection to PostgreSQL via libpq library.
This part of the paper covers only data insertion performance, data retrieval will be discussed in Part II of the paper.
Methods of data insertion in Matlab Database Toolbox
Matlab Database Toolbox provides two methods of database.jdbc.connection class for inserting data, namely, datainsert and fastinsert. turns out that the first one is much faster than the second one (see below graphs displaying results of experiments), so in our performance comparison we pay more attention to datainsert (although some experiments include also fastinsert). But let us have a closer look at how these methods actually work under the hood.
The methods datainsert and fastinsert use so called batch mode allowing to execute several consecutive queries very quickly. The reason for this is as follows. In the batch mode queries are performed via a specially created prepared statement sent to the server in asynchronous mode. That means that all the queries are executed one after another without waiting for their results as a single block called a batch (and that is the main difference from the ordinary synchronous mode where the next query cannot be sent without reading results of the previous query). One may think that at first glance for SQL “INSERT” we do not have any results at all, what is the problem then? But this first impression is deceptive, because internally (on the level of client-server communication) insert statements always return an execution status as a result (plus some extra information in case the execution is failed). And it turns out that usually an essential amount of time is spent just to receive and to process results of each query. Such processing of results cannot be avoided even in case of inserting data. And moreover it may be performed by sufficiently large blocks and only at those instants when the server is ready to return them, so that it is not done after each query execution. Instead it is only done periodically (amidst sending of queries to the server). This explains why datainsert and fastinsert work comparatively quickly (but for some particular types of data and under certain restrictions as will be revealed below). But that does not explain why fastinsert is in the most cases slower than datainsert.
The reason is rather simple. As shows an analysis of source code for these functions fastinsert prepares data within Matlab, creating a Java object of org.postgresql.jdbc.PgPreparedStatement type and filling it tuple by tuple, field by field by calling the respective setters. datainsert also creates an object of the same type corresponding to a special prepared statement, but, in contrast to fastinsert, filling of this object with data is performed in Java instead of Matlab, using a special “writer” object of com.mathworks.toolbox.database.writeTheData type with the following interface:
public class com.mathworks.toolbox.database.writeTheData {
java.lang.String errMessage;
public com.mathworks.toolbox.database.writeTheData();
public double[] doubleWrite(java.sql.PreparedStatement, int, int, int[], double[][], java.lang.String);
public double[] cellWrite(java.sql.PreparedStatement, int, int, int[], java.lang.Object[], java.lang.Object[][], java.lang.String);
public java.lang.String returnException();
}
As can been seen from this interface, this “writer” object works in two modes. Firstly, it can take (via the method doubleWrite) numerical data as a single double matrix assuming that its columns correspond to different fields of some table into which inserting is to be performed. (The fact that these fields may be of different numerical types should not matter, because the necessary typecasting is done further). Secondly, it is possible to pass data as a two-dimensional cell array (by means of the method cellWrite) such that each cell contains some scalar object or a string determining the value for the corresponding field and tuple. The usage of Java for filling the created prepared statement with data makes datainsert impressively quick, but this simultaneously leads to certain latent shortcomings that are not obvious in the beginning.
Methods of data insertion in PgMex
Now let us consider a way to solve the same task via PgMex. This library has also two ways for inserting data. We discuss them both just to give a complete picture, although basically we consider certainly the quickest method. The first, slower, way to insert data is to create a set of parameters (via paramCreate command), then, in a loop for each inserted tuple to assign these parameters to the corresponding values of fields via putf and then execute insert query via paramExec parametrized by given parameters set (it is possible also to reuse the constructed parameters set by paramReset not creating it again and again for each particular tuple). Let us consider the following toy example giving a hint about how it is to be done:
import com.allied.pgmex.pgmexec;
indVec=transpose(1:1000);
nameCVec=repmat({'a';'b'},500,1);
for iTuple=1:nTuples
if iTuple==1
pgParam=pgmexec('paramCreate',dbConn);
else
pgmexec('paramReset',pgParam);
end
pgmexec('putf',pgParam,'%int4 %name',indVec(iTuple),nameCVec{iTuple});
pgmexec('paramExec',dbConn,pgParam,...
'insert into mytable values ($1,$2)');
end
pgmexec('paramClear',pgParam);
But this method turns out to be rather slow. Firstly, because of the overhead related to working with parameters, secondly (and that is more important) - because each execution of paramExec should send the query to the server and then should wait for results of this query before it becomes possible to repeat the procedure. The idea of batch mode we discussed above in a context of datainsert and fastinsert is not used here at all (in fact, the basic purpose of paramExec is to execute parametrized queries reading data).
However this batch mode is implemented in batchParamExec providing the second way to insert data via PgMex (see a lot of examples by the link of how this command is to be used). Actually, batchParamExec does approximately the same as the combination of putf and paramExec discussed above, but without explicit working with parameters (that excludes the mentioned overhead) and much more faster thanks to the batch mode. When it comes to performance, batchParamExec is up to 6 times faster in comparison to the procedure demonstrated by the above example. The respective code is as follows:
import com.allied.pgmex.pgmexec;
SData=struct();
SData.indVec=transpose(1:1000);
SData.nameCVec=repmat({'a';'b'},500,1);
pgmexec('batchParamExec',dbConn,'insert into mytable values ($1,$2)','%int4 %name',SData);
Experiment conditions for comparison between Matlab Database Toolbox and PgMex
In the next subsections below we compare the methods datainsert (and also fastinsert for the simplest experiments) with batchParamExec. In this subsection we give some information on conditions for these experiments. All the testing was done on a box with Intel Core i7-5820K 3.30GHz processor, Asus X99-A motherboard, 64Gb DDR4 RAM running Matlab 2016b on 64-bit Windows 10. PostgreSQL 9.6 data storage was OCZ 256Gb Vector 280 SSD. We used PgMex library v1.1.0.
A couple of words on data used for experiments. This data is based on real daily prices of stocks on some exchanges, so we do not deal below with some toy examples as above. Instead, we try to approximate a real-life usage as much as possible. The fields are as follows (the types pointed in the terms of PostgreSQL):
- t_data of date type determining trading dates
- inst_id of int4 with internal identifiers of instruments (unique for each stock)
- price_low of float4 with low prices of stocks (adjusted for splits)
- price_open of float4 with open prices of stocks (adjusted for splits)
- price_close of float4 with close prices of stocks (adjusted for splits)
- price_close_ini of float4 with close prices of stocks unadjusted for splits
- price_high of float4 with high prices of stocks (adjusted for splits)
- price_close_opt of float4 with close prices of stocks unadjusted for splits and used in the Black-Sholes formula
- volume of int8 with traded volumes
- calc_date of date type with dates when calculations were done
So we have two fields of date type, two fields of integer types (int4 and int8) and 6 fields of float4 type. In all the experiments considered below data is constructed based on this table, but with some modifications to make the respective comparison possible and fit each case. In one case part of fields is excluded, in another case the types of fields along with initial data are changed (the last may seem to be rather artificial, but this is done just for simplicity, avoiding to overload examples with unnecessary details, concentrating ourselves on purely technical problems we have to solve).
It is necessary to note (and this is rather crucial) that all the comparison results depend significantly on the nature of the data to be inserted. So below we consider three cases: pure numerical data, data with timestamps and data with arrays.
Inserting scalar numericals
As was already said above, datainsert can take input data as a numeric matrix. And this turns out to be the most optimal (in terms of performance) case for datainsert. But here we come immediately across an obstacle, because the fields t_data and calc_date are of date type and cannot be put into a numerical matrix in spite of the fact that in Matlab they are naturally represented by serial date numbers. It is required that such values are to be passed into datainsert as strings, so the whole data can be passed only as a cell array (this case is considered in the subsection immediately following this one, see below). Thus, to be able to compare Matlab Database Toolbox with PgMex library for this format of input data we are forced to skip the fields t_data and calc_date from the table and try to insert the remaining ones.
But there is one more shortcoming caused by the fact that these fields are of different sizes and the need to cast them to double Matlab type. Firstly, there is no any guarantee that there is no data loss (because when datainsert is used in a numeric matrix mode everything needs to be converted to double Matlab type, even 8-byte integers). This is not a problem for the fields containing prices like price_low or price_close. But the guarantee is automatically not there when we consider the field volume. This is because whether a field value becomes incorrect after a type transformation or not depends significantly on the value itself. As a result we cannot simple cast all values to double type of Matlab, because size of both double and int64 Matlab types (the latter corresponding to int8 in PostgreSQL) equals 8 bytes. Thus, if we try for example to cast the maximal possible value of int64 equal to 9223372036854775807 to double, you obtain 9223372036854775800 instead of the original value.
But okey, let us assume that there is no data loss. But in this case we have to represent values of all fields by double, thus, essentially increasing the memory size necessary to pass data (almost twice). It can be easily seen that the situation may be potentially even worse if we have fields of logical type along with fields with numerical values (in this case logical values passed into datainsert would occupy in Matlab 8 times more memory than in their initial form).
But this increasing of memory while passing data into datainsert leads to a shortage of memory when the total number of tuples to be inserted is significant. The method fastinsert (although a slower one) faces this problem to a lesser degree, because its sub-optimality in terms of performance becomes an advantage when it comes to a volume of data that may be potentially inserted. This can be clearly seen on the following pictures.
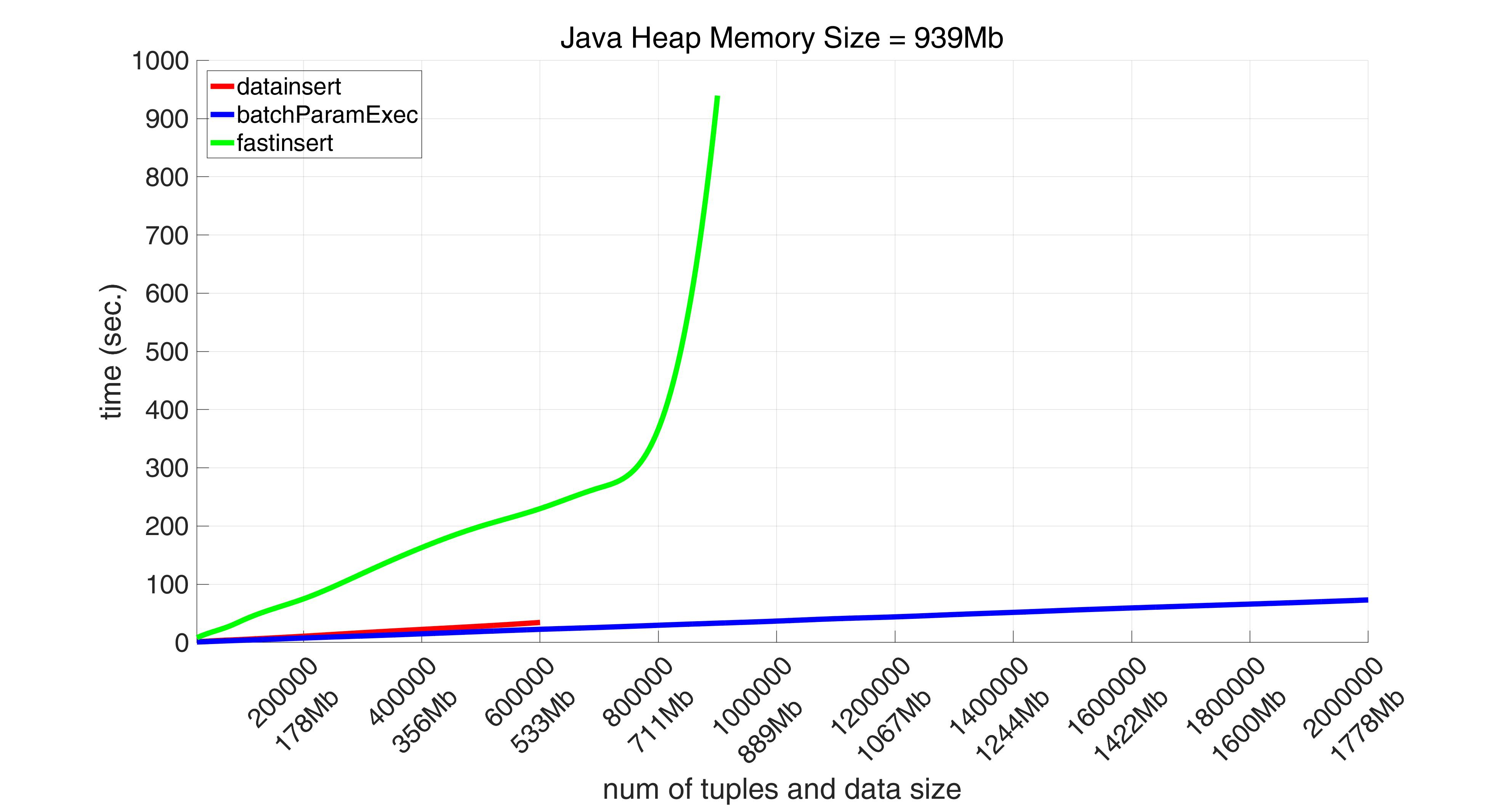
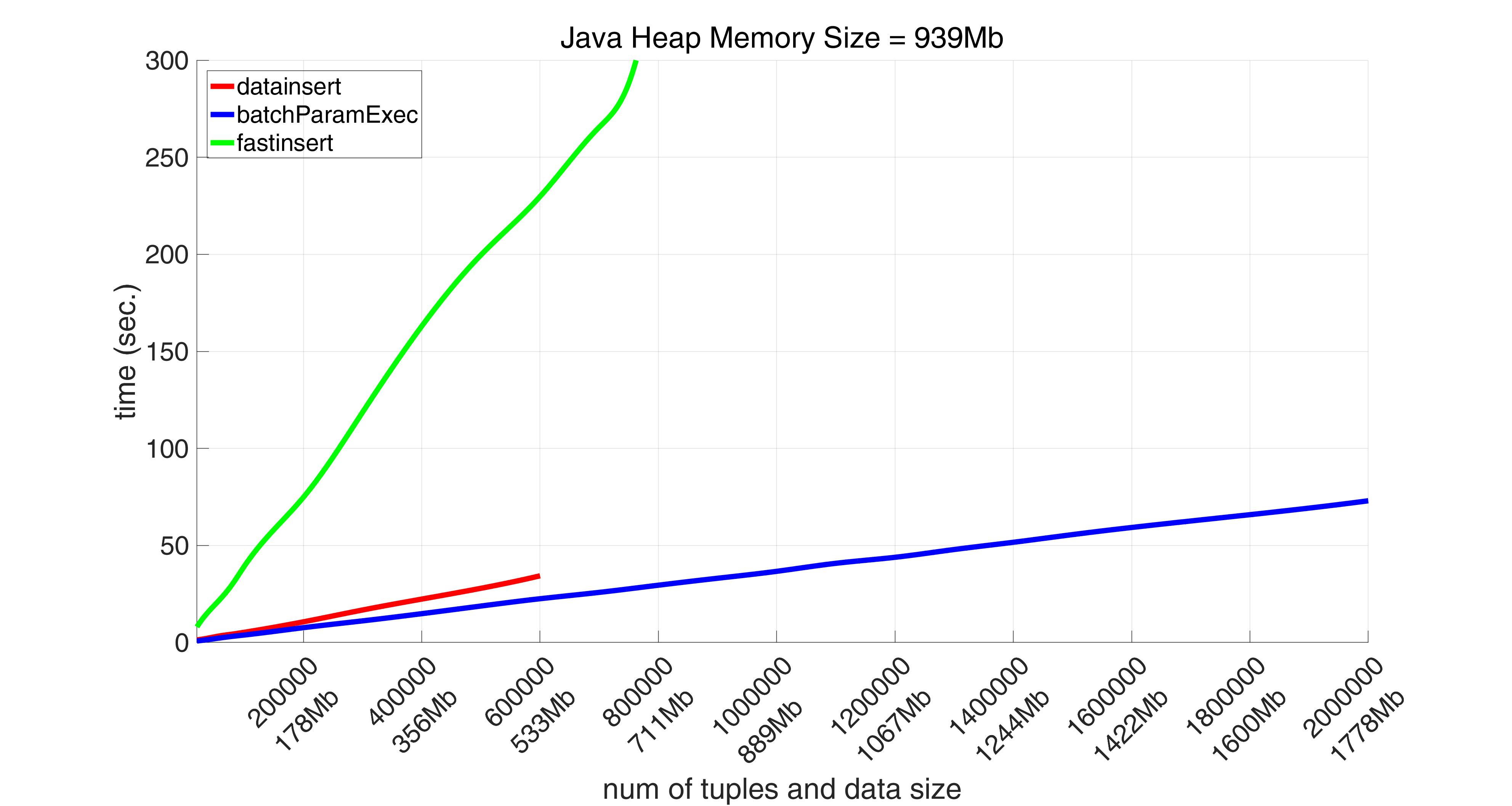
When a number of tuples reaches 700000 (652Mb), datainsert throws the following exception:
Exception for function datainsert, number of tuples 700000
Caused by:
Error using database.jdbc.connection/datainsert (line 258)
Java exception occurred:
java.lang.OutOfMemoryError: GC overhead limit exceeded
at org.postgresql.jdbc.PgPreparedStatement.setDouble(PgPreparedStatement.java:343)
at com.mathworks.toolbox.database.writeTheData.doubleWrite(writeTheData.java:106)
The exception for fastinsert occurs for 1000000 of tuples (889Mb), the exception is as follows:
Exception for function fastinsert, number of tuples 1000000
Caused by:
Failed to retrieve Exception Message
Failed to retrieve Exception Message
Error in database.jdbc.connection/fastinsert (line 282)
StatementObject.setDouble(j,tmp) %NUMERIC, DECIMAL, REAL
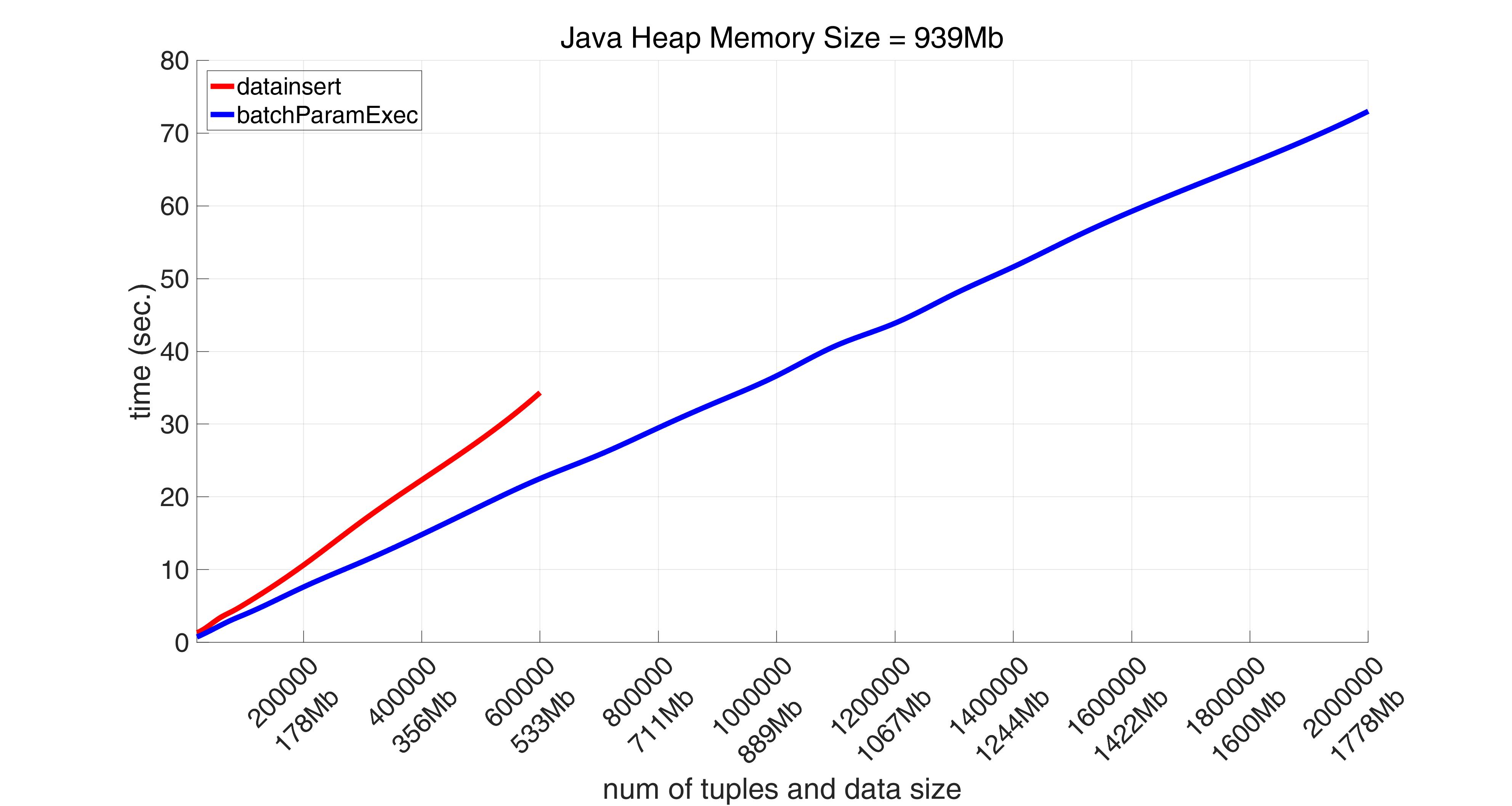
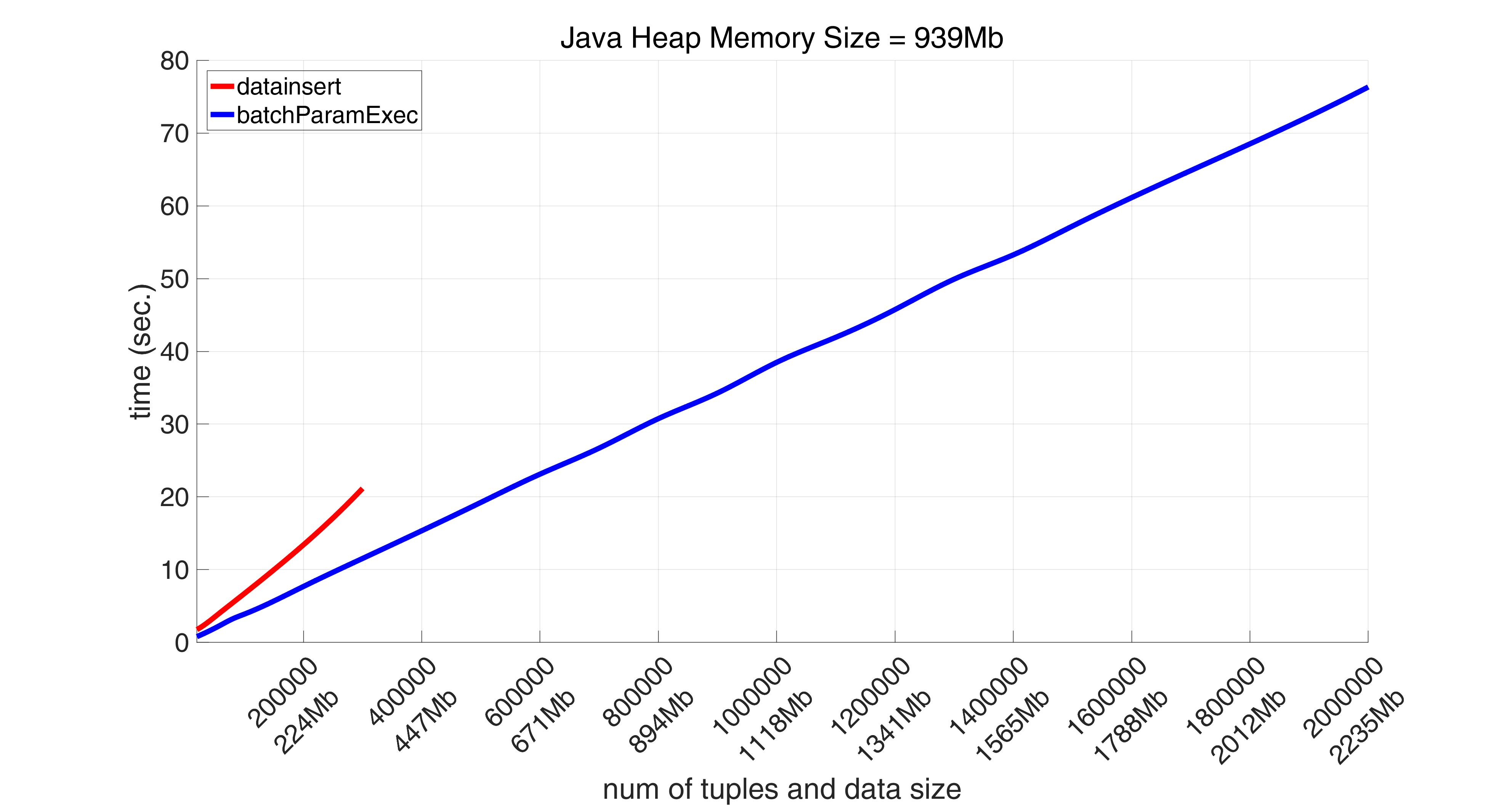
But, as was already mentioned, fastinsert makes this at the expense of performance. Thus this method takes more than 15 minutes to insert 900000 tuples (800Mb), while batchParamExec performs the same job in less than 34 seconds.
Starting with 1000000 tuples batchParamExec method is the only one that successfully manages to perform the task. It inserts 2000000 tuples (1778Mb) in 75 seconds.
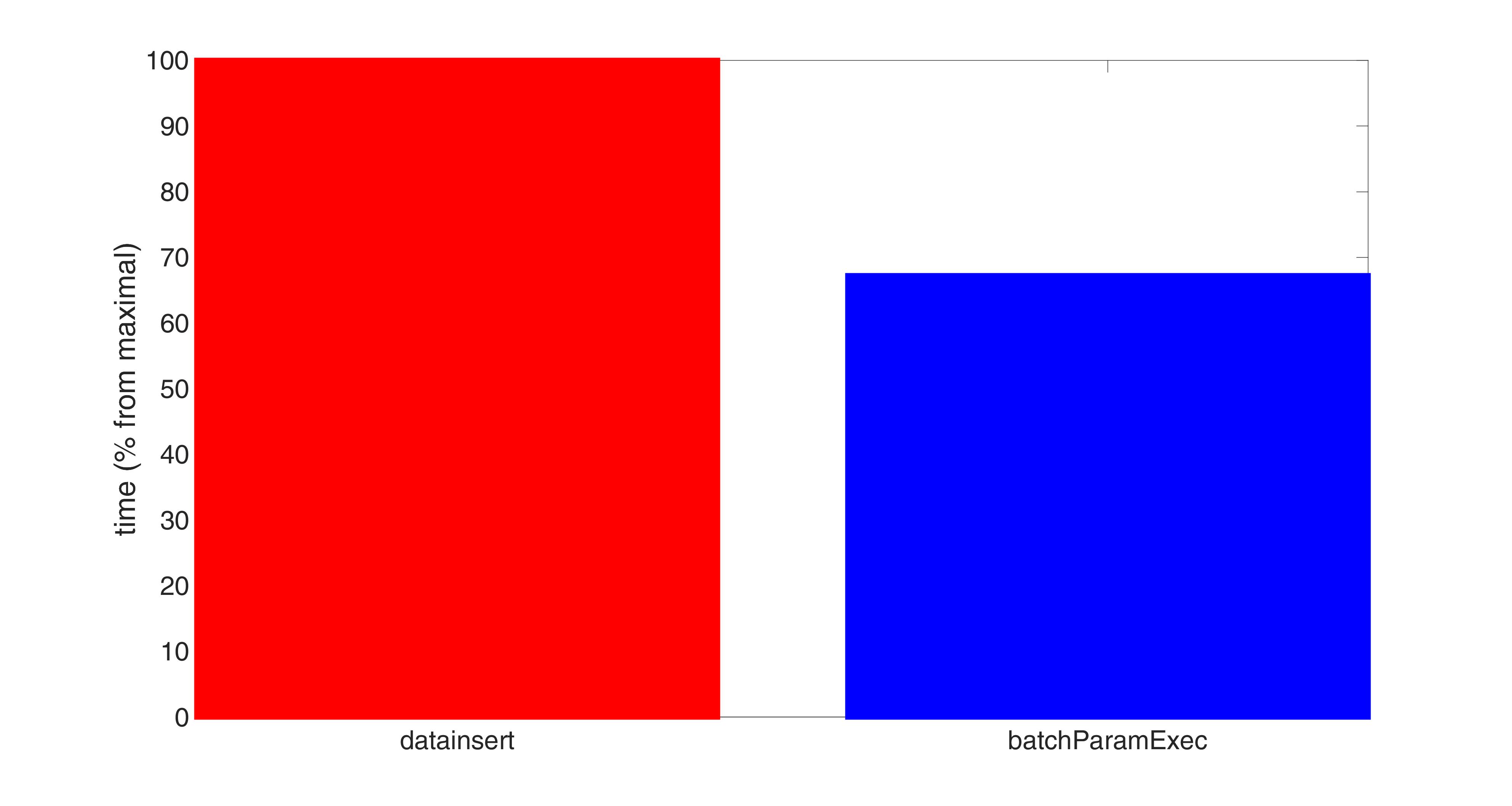
It turns out that if we only take a range [0, 600000] for a number of tuples (as number of tuples = 600000 is where the red graphs ends) on average both datainsert and batchParamExec are more than 8 times faster than fastinsert.
At the same time the execution time for batchParamExec is approximately 70% of that time for datainsert on avarage. Thus batchParamExec is the fastest method, the second is datainsert, the slowest is (as was already mentioned) fastinsert.
Inserting timestamps
The gap in performance between batchParamExec and datainsert becomes even greater when we try to pass input data into datainsert as a two-dimensional cell array, this time inserting the fields t_data and calc_date with dates along with the other ones. As already was said, the method datainsert requires date, time or timestamp values to be converted either (with special formatting) to strings or to java.sql.Date objects. And all the inserted values should be placed in cells of the respective cell array. When in comes to PgMex, no such a conversion is required, date, time and timestamp values may be processed as serial date numbers. The results for data with timestamps passed as strings into datainsert are as follows:
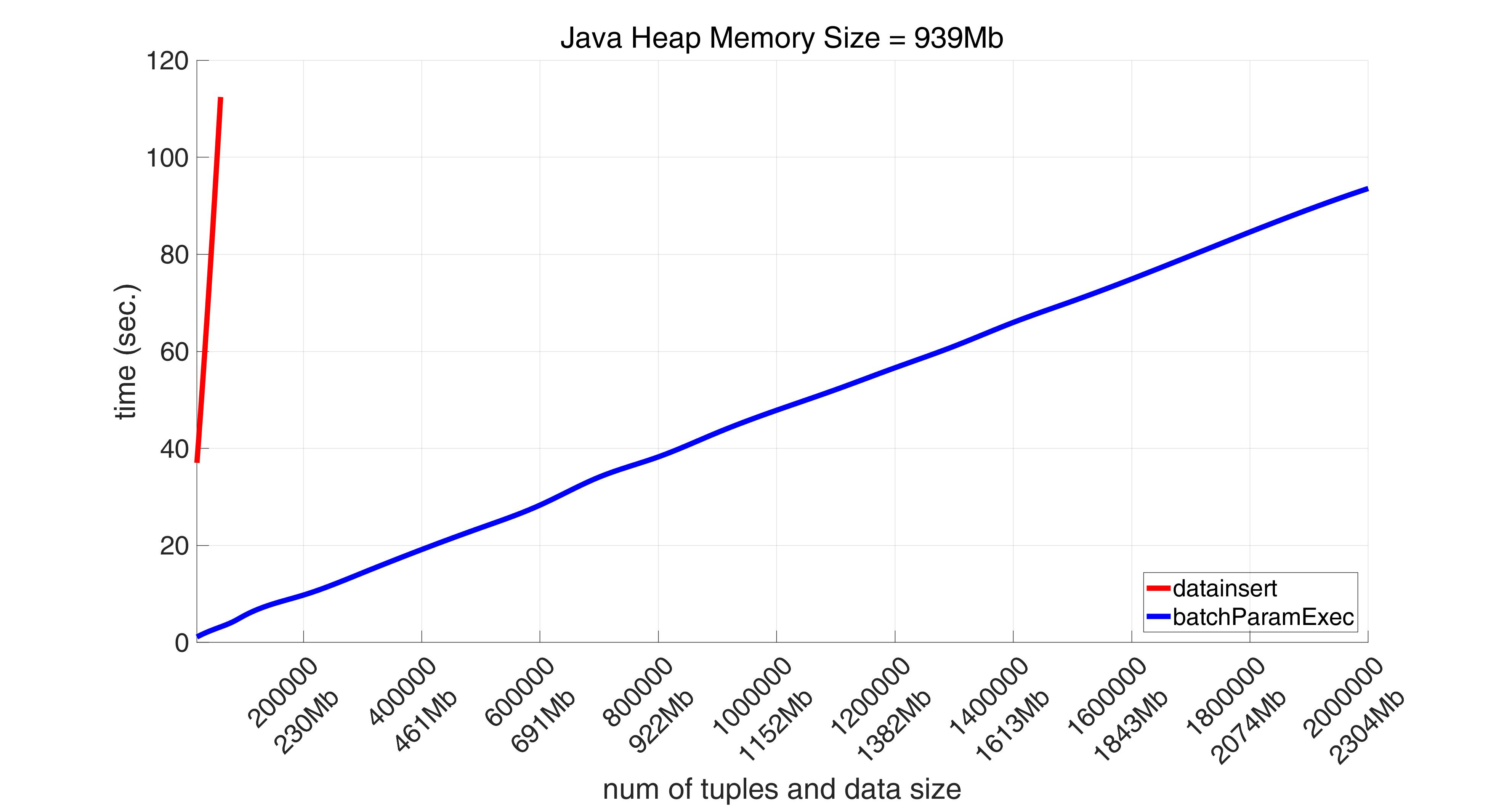
It can be easily seen that datainsert reaches 300000 tuples (335Mb) (thanks to absence of converting numbers to some types of greater size), but fails to insert 500000 tuples (559Mb) by throwing this exception:
Exception for function datainsert, number of tuples 500000
Caused by:
Error using database.jdbc.connection/datainsert (line 256)
Java exception occurred:
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.String.substring(Unknown Source)
at java.sql.Date.valueOf(Unknown Source)
at com.mathworks.toolbox.database.writeTheData.cellWrite(writeTheData.java:185)
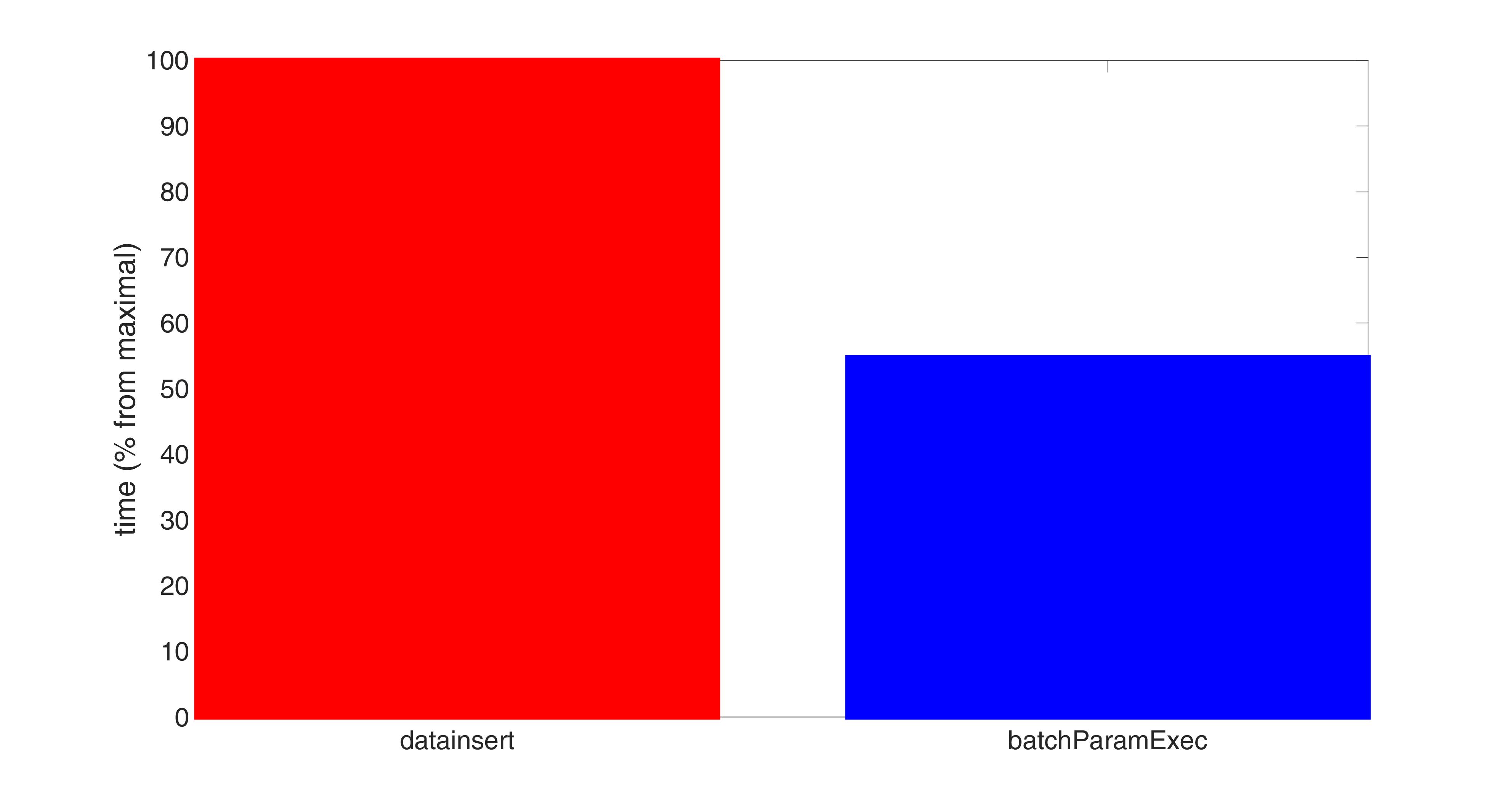
Besides, on average the execution time for batchParamExec is less than 60% of that time for datainsert, at least for those volumes both function succeeded to insert.
Inserting arrays
The most difficult situation occurs when it is necessary to pass values for fields of array types. This may occur when we need to insert time series (or even multidimensional arrays like those we have for implied volatility surfaces) or values of vector-valued factors/features. Here just to give a hint about what the situation turns into we simply transform the above data making all the fields except for t_data and calc_date (these remain intact) arrays of the same types (for inst_id int4 turns into int4[]) and transforming each scalar value to an array simply by replicating the original value (in the experiments below all the arrays are 1x2).
And here both datainsert and fastinsert stumble upon huge obstacles. Firstly fastinsert doesn’t allow to insert arrays at all (excluding byte arrays, for example, images, which is a very special case). Thus we are left with only datainsert.
But using this method is also problematic, because even if data is passed into datainsert as a two-dimensional cell array, each cell is in any case assumed to contain a scalar object. Thus, to pass arrays it is necessary to convert them to org.postgresql.jdbc.PgArray objects, this may be done as follows. First an array of the Java type corresponding to given Matlab type is created (for instance, an array of java.lang.Float for single Matlab array) by means of calling javaArray. After the Java array is filled with values of the mentioned Matlab array, each one is converted to the corresponding Java type. And, finally, this Java array is transformed to org.postgresql.jdbc.PgArray by calling createArrayOf method of org.postgresql.jdbc.PgConnection object stored as Handle property of the JDBC connection object of database.jdbc.connection class. Not an easy procedure, not to mention that all this takes a huge amount of time, which makes it almost impossible to use Matlab Database Toolbox (as can be seen from the results of experiments below) for inserting a more or less material amount of array-like data.
In contrast to this, PgMex uses Matlab native data types to pass such data. For example, it can be done via cell arrays, when each cell contains a value of given field for the corresponding tuple. But there are ways to speed this up even more. Let us consider a case when all values for some array-typed field in a table have the same size across all tuples and size of each value across all tuples along the first dimension equals 1 (as we see, this is the case when all our values have size 1x2). In such cases all these arrays values can be stacked up one above the other by concatenating them along the first dimension. Once this is done, all these values may be passed as a single (in the general case - multidimensional) array without any conversion of their elements.
The results of performance comparison between datainsert and batchParamExec for the case of data with arrays are as follows:
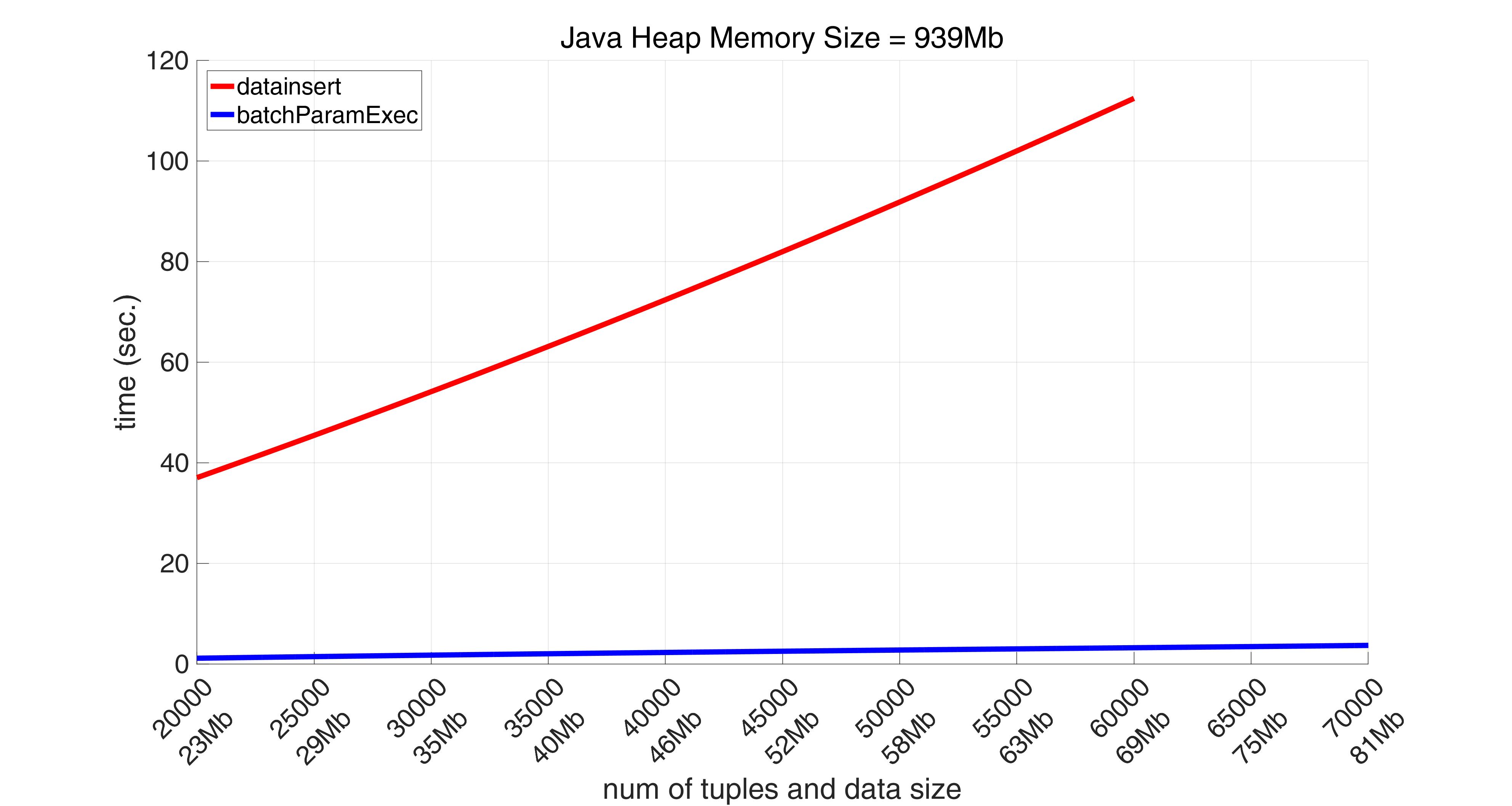
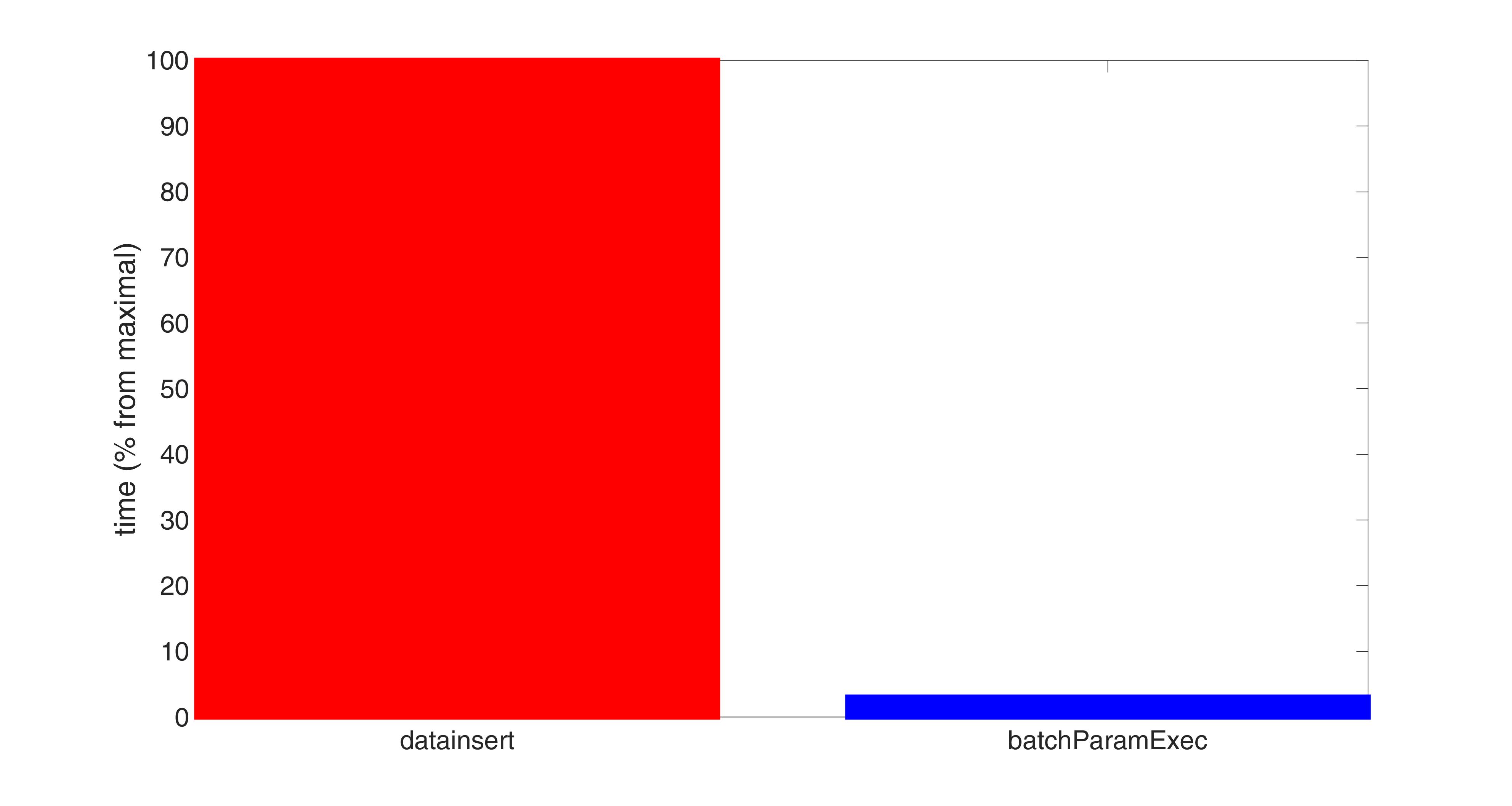
Naturally we included the overhead time for transformation of arrays required for datainsert into its total time displayed on the pictures. And it is on average more than 30 times (!) slower than that of batchParamExec. Not to say that datainsert does not allow to insert 80000 tuples, just 92Mb in size, throwing the following exception:
Exception for function datainsert, number of tuples 80000
Caused by:
Error using database.jdbc.connection/datainsert (line 256)
Java exception occurred:
java.lang.OutOfMemoryError: Java heap space
at java.lang.StringCoding.encode(Unknown Source)
at java.lang.String.getBytes(Unknown Source)
at org.postgresql.core.Utils.encodeUTF8(Utils.java:53)
at org.postgresql.core.v3.SimpleParameterList.getV3Length(SimpleParameterList.java:339)
at org.postgresql.core.v3.QueryExecutorImpl.sendBind(QueryExecutorImpl.java:1449)
at org.postgresql.core.v3.QueryExecutorImpl.sendOneQuery(QueryExecutorImpl.java:1767)
at org.postgresql.core.v3.QueryExecutorImpl.sendQuery(QueryExecutorImpl.java:1294)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:446)
at org.postgresql.jdbc.PgStatement.executeBatch(PgStatement.java:793)
at org.postgresql.jdbc.PgPreparedStatement.executeBatch(PgPreparedStatement.java:1659)
at com.mathworks.toolbox.database.writeTheData.cellWrite(writeTheData.java:284)
But okey, let us see what if we take into account only “pure” time, i.e. if we measure only how long datainsert itself works.
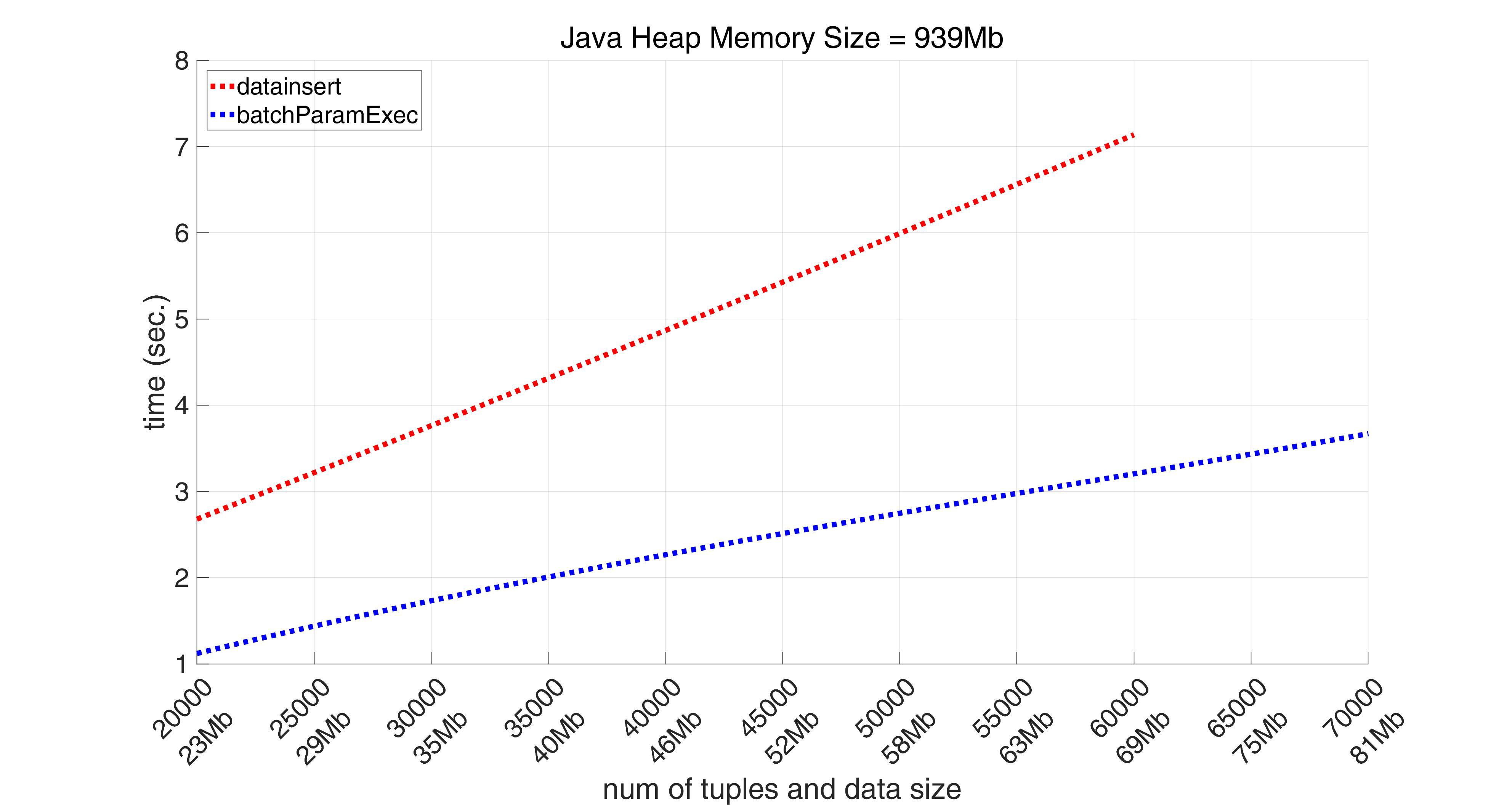
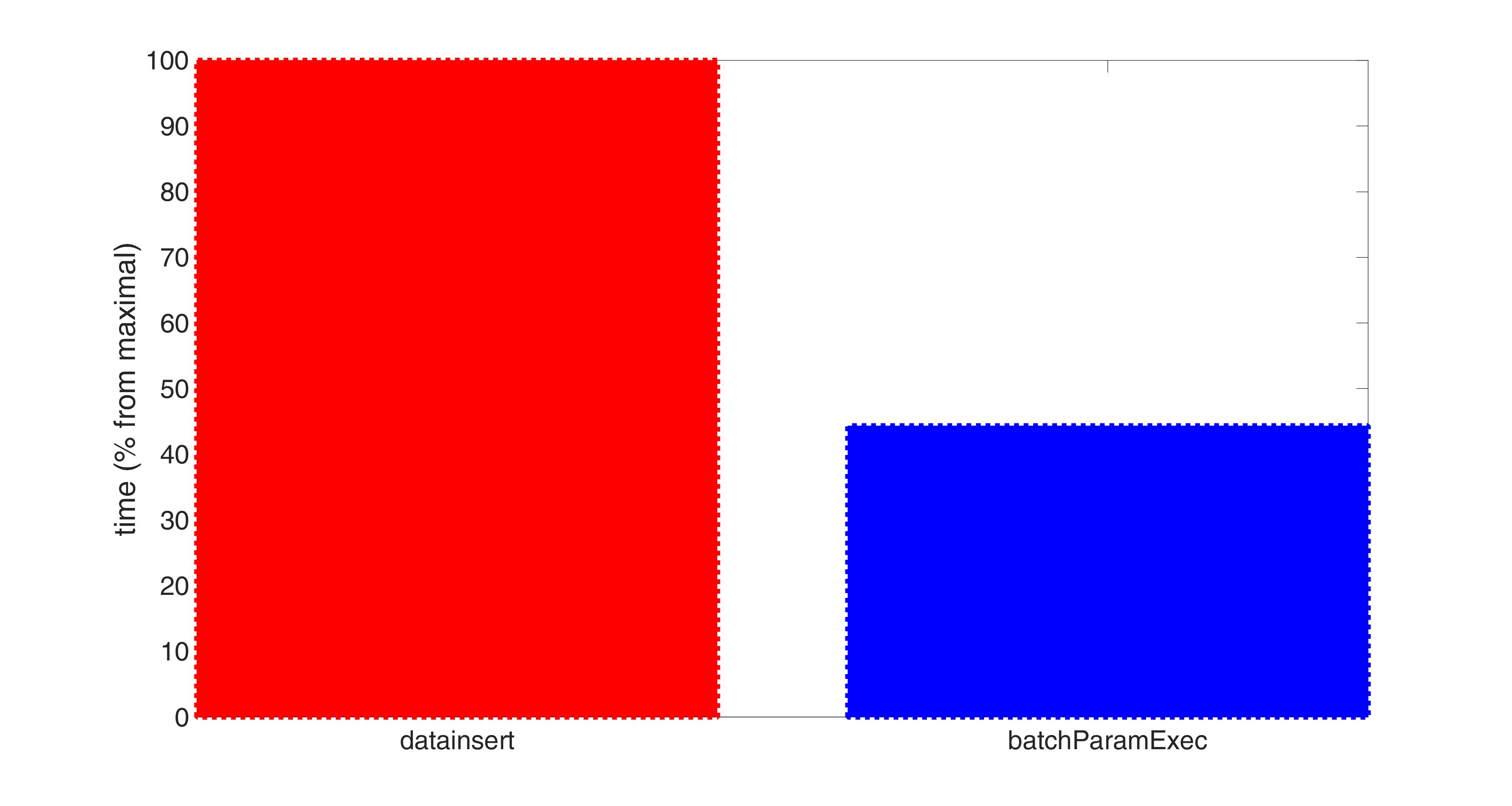
And in this case we see that datainsert works 2 times slower than batchParamExec.
Summary
So as we have seen, the functionality provided by Matlab Database Toolbox for JDBC connection to PostgreSQL have serious restrictions, especially in case of big data and presence of arrays. Namely working with arrays was the main stimulus for implementation of PgMex library, whose limits are sufficiently higher and that is free from those shortcomings related to data types conversions (because it works with native Matlab formats). We left beyond the scope of this paper the question of how to work with NULL values. In short, it may be said in this regard PgMex library has rather natural and direct ways of working with NULLs, while in Matlab Database Toolbox the corresponding mechanisms are different for reading and writing data, very restrictive and intricate in terms of functionality.
In Part II of this paper we will compare different ways to retrieve data from the database using both Matlab Database Toolbox and PgMex library. But we can announce here that retrieval by means of exec and fetch methods from Matlab Database Toolbox of data having simple scalar types is at least 3.5 times slower then the one performed via exec and getf of PgMex library.